
如果Redis的读写请求量很大,那么单个实例很有可能承担不了这么大的请求量,如何提高Redis的性能呢?你也许已经想到了,可以部署多个副本节点,业务采用读写分离的方式,把读请求分担到多个副本节点上,提高访问性能。要实现读写分离,就必须部署多个副本,每个副本需要实时同步主节点的数据。
Redis也提供了完善的主从复制机制,使用非常简单的命令,就可以构建一个多副本节点的集群。
同时,当主节点故障宕机时,我们可以把一个副本节点提升为主节点,提高Redis的可用性。可见,对于故障恢复,也依赖Redis的主从复制,它们都是Redis高可用的一部分。
这篇文章我们就来介绍一下Redis主从复制流程和原理,以及在复制过程中有可能产生的各种问题。
构建主从复制集群
假设我们现在有一个节点A,它经过写入一段时间的数据写入后,内存中保存了一些数据。
此时我们再部署一个节点B,需要让节点B成为节点A的数据副本,并且之后与节点A保持实时同步,如何做呢?
Redis提供了非常简单的命令:slaveof。我们只需要在节点B上执行以下命令,就可以让节点B成为节点A的数据副本:
1
|
slaveof 节点A_host:节点A_port
|
节点B就会自动与节点A建立数据同步,如果节点A的数据量不大,等待片刻,就能看到节点B拥有与节点A相同的数据,同时在节点A上产生的数据变更,也会实时同步到节点B上。
通过这样简单的方式,我们可以非常方便地构建一个master-slave集群,业务可以在master上进行写入,在slave上读取数据,实现读写分离,提高访问性能。
那么主从节点的复制是如何进行的?下面我们就来分析其中的原理。
主从复制流程
为了方便下面讲解,我们这里把节点A叫做master节点,节点B叫做slave节点。
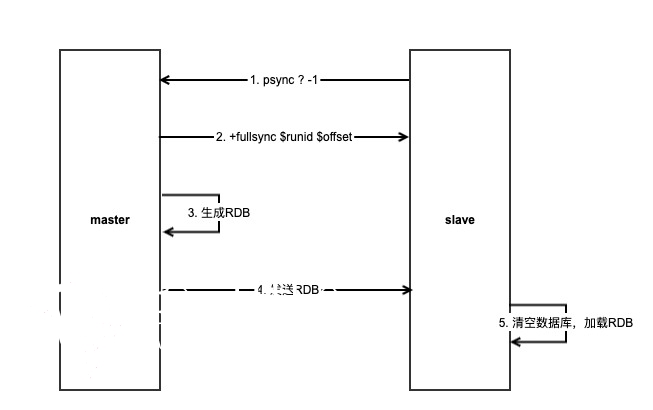
当我们在slave上执行slaveof命令时,这个复制流程会经过以下阶段:
- slave发送
psync $runid $offset给master,请求同步数据 - master检查slave发来的
runid和offset参数,决定是发送全量数据还是部分数据 - 如果slave是第一次与master同步,或者master-slave断开复制太久,则进行全量同步
- master在后台生成RDB快照文件,通过网络发给slave
- slave接收到RDB文件后,清空自己本地数据库
- slave加载RDB数据到内存中
- 如果master-slave之前已经建立过数据同步,只是因为某些原因断开了复制,此时只同步部分数据
- master根据slave发来的数据位置
offset,只发送这个位置之后的数据给slave - slave接收这些差异数据,更新自己的数据,与maser保持一致
- master根据slave发来的数据位置
- 之后master产生的写入,都会传播一份给slave,slave与master保持实时同步
下面分别介绍全量同步和部分同步的详细流程。
全量同步
当我们在节点B上执行slaveof命令后,节点B会与节点A建立一个TCP连接,然后发送psync $runid $offset命令,告知节点A需要开始同步数据。
这两个参数的具体含义如下:
runid:master节点的唯一标识offset:slave需要从哪个位置开始同步数据
什么是runid?在启动Redis实例时,Redis会为每个实例随机分配一个长度为40位的十六进制字符串,用来标识实例的唯一性,也就是说,runid就是这个实例的唯一标识。
由于是第一次同步,slave并不知道master的runid,所以slave会r发送psync ? -1,表示需要全量同步数据。
master在收到slave发来的psync后,会给slave回复+fullsync $runid $offset,这个runid就是master的唯一标识,slave会记录这个runid,用于后续断线重连同步请求。
之后master会在后台生成一个RDB快照文件,RDB文件生成的过程可以参考我之前写的这篇文章::Redis的持久化如何做的?RDB和AOF对比分析。
RDB文件生成之后,master把这个RDB文件通过网络发送给slave,slave收到RDB文件后,清空整个实例,然后加载这个RDB数据到内存中,此时slave拥有了与master接近一致的数据。
为什么是接近一致?因为master在生成RDB和slave加载RDB的过程是比较耗时的,在这个过程中,master产生新的写入,这些新写入的命令目前在slave上是没有执行的。这些命令master如何与slave保持一致呢?
Redis会把这些增量数据写入到一个叫做复制缓冲区(repl_baklog)的地方暂存下来,这个复制缓冲区是一个固定大小的队列,由配置参数repl-backlog-size决定,默认1MB,可以通过配置文件修改它的大小。
由于是固定大小的队列,所以如果这个缓冲区被写满,那么它之前的内容会被覆盖掉。
注意:无论slave有多少个,master的复制缓冲区只有一份,它实际上就是暂存master最近写入的命令,供多个slave部分同步时使用。
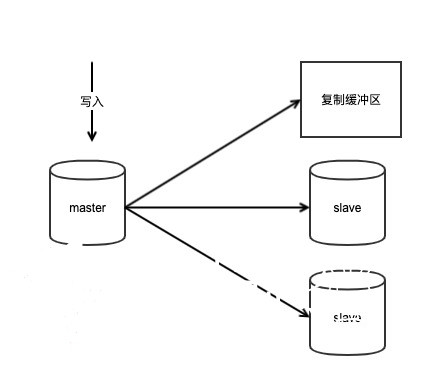
待slave加载RDB文件完成之后,master会把复制缓冲区的这些增量数据发送给slave,slave依次执行这些命令,就能保证与master拥有相同的数据。
之后master再收到的写命令,会实时传播给slave节点,slave与master执行同样的命令,这样slave就可以与master保持实时数据的同步。
部分同步
如果在复制过程中,因为网络抖动或其他原因,导致主从连接断开,等故障恢复时,slave是否需要重新同步master的数据呢?
在Redis的2.8版本之前,确实是这么干的,每次主从断开复制,重新连接后,就会触发一次全量数据的同步。
可见,这么做的代价是非常大的,而且耗时耗力。后来在Redis在这方面进行了改进,在2.8版本之后,Redis支持部分同步数据。
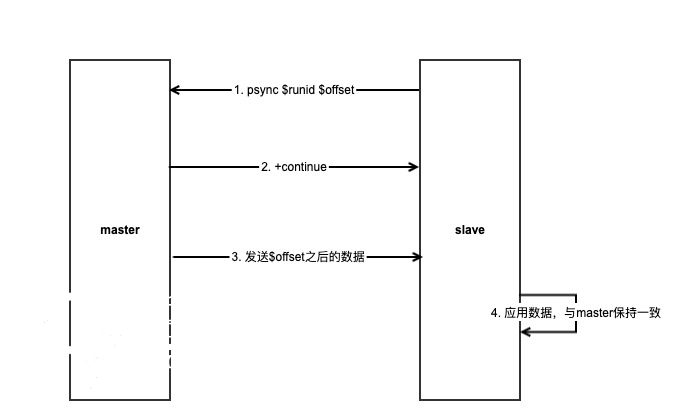
当主从断开重新建立连接后,slave向master发送同步请求:psync $runid $offset,因为之前slave在第一次全量同步时,已经记录下了master的runid,并且slave也知道目前自己复制到了哪个位置offset。
这时slave就会告知master,之前已经同步过数据了,这次只需要把offset这个位置之后的数据发送过来就可以了。
master收到psync命令之后,检查slave发来的runid与自身的runid一致,说明之前已经同步过数据,这次只需要同步部分数据即可。
但是slave需要的offset之后的数据,master还保存着吗?
前面我们介绍了master自身会有一个复制缓冲区(repl-backlog),这个缓冲区暂存了最近写入的命令,同时记录了这些命令的offset位置。此时master就会根据slave发来的这个offset在复制缓冲区中查询是否还保留着这个位置之后的数据。
如果有,那么master给slave回复+continue,表示这次只同步部分数据。之后master把复制缓冲区offset之后的数据给slave即可,slave执行这些命令后就与master达到一致。
如果master复制缓冲区找不到offset之后的数据,说明断开的时间太久,复制缓冲区的内容已经被新的内容覆盖了,此时master只能触发全量数据同步。
命令传播
slave经过全量同步或部分同步后,之后master实时产生的写入,是如何实时同步的?
很简单,master每次执行完新的写入命令后,也会把这个命令实时地传播给slave,slave执行与master相同的操作,就可以实时与master保持一致。
需要注意的是,master传播给slave的命令是异步执行的,也就是说在master上写入后,马上在slave上查询是有可能查不到的,因为异步执行存在一定的延迟。
slave与master建立连接后,slave就属于master的一个client,master会为每个client分配一个client output buffer,master和每个client通信都会先把数据写入到这个内存buffer中,再通过网络发送给这个client。
但是,由于这个buffer是占用Redis实例内存的,所以不能无限大。所以Redis提供了控制buffer大小的参数限制:
[php]# 普通client buffer限制
client-output-buffer-limit normal 0 0 0
# slave client buffer限制
client-output-buffer-limit slave 256mb 64mb 60
# pubsub client buffer限制
client-output-buffer-limit pubsub 32mb 8mb 60
[/php]
这个参数的格式为:client-output-buffer-limit $type $hard_limit $soft_limit $soft_seconds,其含义为:如果client的buffer大小达到了hard_limit或在达到了soft_limit并持续了soft_seconds时间,那么Redis会强制断开与client的连接。
对于slave的client,默认的限制是,如果buffer达到了256MB,或者达到64MB并持续了1分钟,那么master就会强制断开slave的连接。
这个配置的大小在某些场景下,也会影响到主从的数据同步,我们下面会具体介绍到。
心跳机制
在命令传播阶段,为了保证master-slave数据同步的稳定进行,Redis还设计了一些机制维护这个复制链路,这种机制主要通过心跳来完成,主要包括两方面:
- master定时向slave发送
ping,检查slave是否正常 - slave定时向master发送
replconf ack $offset,告知master自己复制的位置
在master这一侧,master向slave发送ping的频率由repl-ping-slave-period参数控制,默认10秒,它的主要作用是让slave节点进行超时判断,如果slave在规定时间内没有收到master的心跳,slave会自动释放与master的连接,这个时间由repl-timeout决定,默认60秒。
同样,在slave这边,它也会定时向master发送replconf ack $offset命令,频率为每1秒一次,其中offset是slave当前复制到的数据偏移量,这么做的主要作用如下:
- 让master检测slave的状态:如果master超过
repl-timeout时间未收到slave的replconf ack $offset命令,则master主动断开与slave的连接 - master检测slave丢失的命令:master根据slave发送的
offset并与自己对比,如果发现slave发生了数据丢失,master会重新发送丢失的数据,前提是master的复制缓冲区中还保留这些数据,否则会触发全量同步 - 数据安全性保障:Redis提供了
min-slaves-to-write和min-slaves-max-lag参数,用于保障master在不安全的情况下禁止写入,min-slaves-to-write表示至少存在N个slave节点,min-slaves-max-lag表示slave延迟必须小于这个时间,那么master才会接收写命令,否则master认为slave节点太少或延迟过大,这种情况下是数据不安全的,实现这个机制就依赖slave定时发送replconf ack $offset让master知晓slave的情况,一般情况下,我们不会开启这个配置,了解一下就好
可见,master和slave节点通过心跳机制共同维护它们之间数据同步的稳定性,并在同步过程中发生问题时可以及时自动恢复。
我们可以可以在master上执行info命令查看当前所有slave的同步情况:
[php]role:master # redis的角色
connected_slaves:1 # slave节点数
slave0:ip=127.0.0.1,port=6480,state=online,offset=22475,lag=0 # slave信息、slave复制到的偏移位置、距离上一次slave发送心跳的时间间隔(秒)
master_repl_offset:22475 # master当前的偏移量
repl_backlog_active:1 # master有可用的复制缓冲区
repl_backlog_size:1048576 # master复制缓冲区大小[/php]
通过这些信息,我们能看到slave与master的数据同步情况,例如延迟了多大的数据,slave多久没有发送心跳给master,以及master的复制缓冲区大小。
复制过程中的问题
在整个数据复制的过程中,故障是时有发生的,例如网络延迟过大、网络故障、机器故障等。
所以在复制过程中,有一些情况需要我们格外注意,必要时需要针对性进行参数配置的调整,否则同步过程中会发生很多意外问题。
主要问题分为以下几个方面,下面依次来介绍。
主从断开复制后,重新复制触发了全量同步?
上面我们有提到,主从建立同步时,优先检测是否可以尝试只同步部分数据,这种情况就是针对于之前已经建立好了复制链路,只是因为故障导致临时断开,故障恢复后重新建立同步时,为了避免全量同步的资源消耗,Redis会优先尝试部分数据同步,如果条件不符合,才会触发全量同步。
这个判断依据就是在master上维护的复制缓冲区大小,如果这个缓冲区配置的过小,很有可能在主从断开复制的这段时间内,master产生的写入导致复制缓冲区的数据被覆盖,重新建立同步时的slave需要同步的offset位置在master的缓冲区中找不到,那么此时就会触发全量同步。
如何避免这种情况?解决方案就是适当调大复制缓冲区repl-backlog-size的大小,这个缓冲区的大小默认为1MB,如果实例写入量比较大,可以针对性调大此配置。
但这个配置不能调的无限大,因为它会额外占用内存空间。如果主从断开复制的时间过长,那么触发全量复制在所难免的,我们需要保证主从节点的网络质量,避免频繁断开复制的情况发生。
master写入量很大,主从断开复制?
主从经过全量同步和部分同步后,之后master产生了写入命令,会实时传播给slave节点,如果在这个过程中发生了复制断开,那么一定是在这个过程中产生了问题。我们来分析这个过程是如何处理命令传播的。
上面我们也提到了,主从建立同步链路后,由于slave也是master的一个client,master会对每个client维护一个client output buffer,master产生写命令执行完成后,会把这个命令写入到这个buffer中,然后等待Redis的网络循环事件把buffer中数据通过Socket发送给slave,发送成功后,master释放buffer中的内存。
如果master在写入量非常大的情况下,可能存在以下情况会导致master的client output buffer内存持续增长:
- 主从节点机器存在一定网络延迟(例如机器网卡负载比较高),master无法及时的把数据发送给slave
- slave由于一些原因无法及时处理master发来的命令(例如开启了AOF并实时刷盘,磁盘IO负载高)
当遇到上面情况时,master的client output buffer持续增长,直到触发默认配置的阈值限制client-output-buffer-limit slave 256mb 64mb 60,那么master则会把这个slave连接强制断开,这就会导致复制中断。
之后slave重新发送复制请求,但是以上原因可能依旧存在,经过一段时间后又产生上述问题,主从连接再次被断开,周而复始,主从频繁断开链接,无法正常复制数据。
解决方案是,适当调大client-output-buffer-limit的阈值,并且解决slave写入慢的情况,保证master发给slave的数据可以很快得处理完成,这样才能避免频繁断开复制的问题。
添加slave节点,master发生阻塞?
当主从建立同步进行全量同步数据时,master会fork出一个子进程,扫描全量数据写入到RDB文件中。具体可以参考我之前写的文章,分析了RDB的原理:Redis的持久化如何做的?RDB和AOF对比分析。
这个fork操作,并不是没有代价的。fork在创建子进程时,需要父进程拷贝一份内存页表给子进程,如果master占用的内存过大,那么fork时需要拷贝的内存页表也会比较耗时,在完成fork之前,Redis整个进程都会阻塞住,无法处理任何的请求,所以业务会发现Redis突然变慢了,甚至发生超时的情况。
我们可以执行info可以看到latest_fork_usec参数,单位微妙。这就是最后一次fork的耗时时间,我们可以根据这个时间来评估fork时间是否符合预期。
对于这种情况,可以优化方案如下:
- 一定保证机器拥有足够的CPU资源和内存资源
- 单个Redis实例内存不要太大,大实例拆分成小实例
通过以上方式避免fork引发的父进程长时间阻塞问题。
主从全量同步数据时很慢?
之前我们已经了解到,主从全量复制会经过3个阶段:
- master生成RDB文件
- master把RDB文件发送给slave
- slave清空数据库,加载RDB文件到内存
如果发现全量同步数据非常耗时,我们根据以上阶段来分析原因:
- master实例数据比较大,并且机器的CPU负载较高时,在生成RDB时耗大量CPU资源,导致RDB生成很慢
- master和slave的机器网络带宽被打满,导致master发送给slave的RDB文件网络传输时变慢
- slave机器内存不够用,但开启了swap机制,导致内存不足以加载RDB文件,数据被写入到磁盘上,导致数据加载变慢
通过以上情况可以看出,主从复制时,会消耗CPU、内存、网卡带宽各方面的资源,我们需要合理规划服务器资源,保证资源的充足。并且针对大实例进行拆分,能避免很多复制中的问题。
总结
这篇文章我们介绍了Redis主从复制的流程和工作原理,以及在复制过程中可能引发的问题。
虽然搭建一个复制集群很简单,但其中涉及到的细节也很多。Redis在复制过程也可能存在各种问题,我们需要设置合适的配置参数和合理运维Redis,才能保证Redis有稳定可用的副本数据,为我们的高可用提供基础。
